
: Antonio Salis, R&D Project Manager, Engineering Sardegna
and Roberto Bulla, Senior Software Architect, Engineering Sardegna
Serverless technology and Function-as-a-Service terms have gained so much attention in the development community, and are one of the most valuable tools available to developers today. Gartner has referred to serverless technology in their annual Top 10 Strategic Technology Trends for 2017, referencing it to be a part of MASA, “the mesh app and service architecture (MASA)” as “a multichannel solution architecture that leverages cloud and serverless computing, containers and microservices as well as APIs and events to deliver modular, flexible and dynamic solutions”. This is a long-term approach which will need IT to adopt new tools and frameworks.

Serverless includes servers
First tool is Serverless, which is a method of providing backend (third-party) services on an as-used basis, an approach that replaces long-running virtual machines with ephemeral compute power that comes into existence on request and disappears immediately after use. Serverless architecture is an umbrella which includes backend-as-a-service (BaaS) and Function-as-a-service (FaaS). Functions are small code packages which runs inside containers. They are invoked due to specific event and die once the specific task is finished. Users can write and deploy code without worrying about the underlying physical or virtual infrastructure. A company that gets backend services from a serverless vendor is charged based on their usage (e.g. computation, memory, service execution time, etc.) and do not have to reserve and pay for a fixed amount of bandwidth or number of servers, as the service is auto-scaling.
Note that although called serverless, physical servers are still used but developers do not need to be aware of them. What makes serverless different from cloud computing and server-less is that servers are not always running and spinning. Also, IT companies don’t have to manage servers or worry about their scaling.
Advantages of Serverless computing
No server management is necessary
The rise of serverless has decoupled application delivery from infrastructure management and ownership. It means that it has enabled developers to focus solely on application development without ever worrying about managing servers and service availability. Serverless providers are solely responsible for your infrastructure management and in charge of all system scaling matters. This, in turn, makes possible for IT companies to focus more on innovation with a reduced time to market.
Cost reduction, only used resources are charged
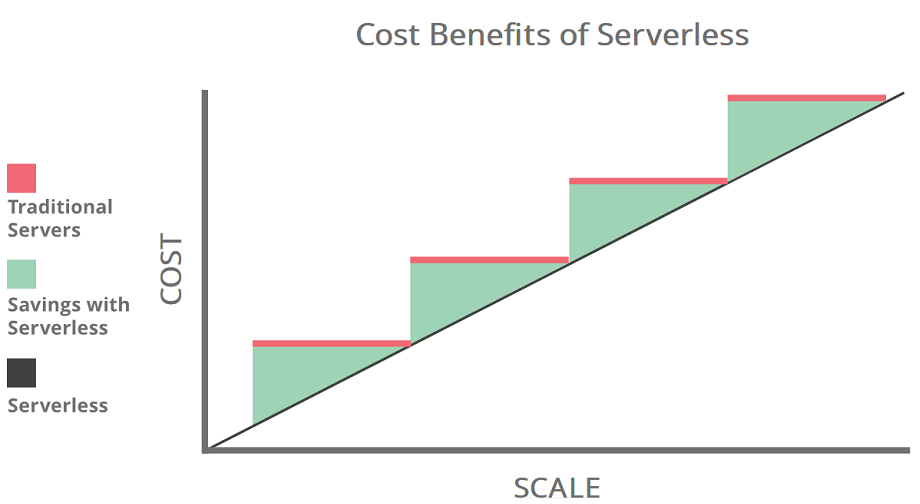
Serverless users are only charged for what they use. Code only runs when backend functions are needed by the serverless application, and the code automatically scales up as needed. Provisioning is dynamic, precise, and real-time. Some services are so exact that they break their charges down into 100-millisecond increments. In contrast, in a traditional ‘server-full’ architecture, developers have to project in advance how much server capacity they will need and then purchase that capacity, whether they end up using it or not. According to a recent research run by a leading cloud management company, most of virtual machine instances run at load lower than 20%. The following diagram represent the costs comparison, highlighting the benefits coming from the serverless adoption.
Serverless architectures are inherently scalable
Imagine if the post office could somehow magically add and decommission delivery trucks at will, increasing the size of its fleet as the amount of mail spikes and decreasing its fleet for times when fewer deliveries are necessary. That’s essentially what serverless applications are able to do.
Applications built with a serverless infrastructure will scale automatically as the user base grows or usage increases. If a function needs to be run in multiple instances, the vendor’s servers will start up, run, and end them as they are needed, often using containers (the functions start up more quickly if they have been run recently). Even the overall resiliency is increased: since each function is executed independently from others, any function failure does not affect the overall application performance. As a result, a serverless application will be able to handle an unusually high number of requests just as well as it can process a single request from a single user. A traditionally structured application with a fixed amount of server space can be overwhelmed by a sudden increase in usage.
Code Application development could have some important benefits
Because Looking at serverless architectures from the application development point of view, its adoption has some relevant benefits. First, with a wide variety of available third-party services and the code stripped down to writing functions, developers can focus on user experience and create truly powerful applications with lots of useful features and friendly interfaces. Moreover each component of the whole application plays a more architectural aware role, like in the microservices approach. Systems built in this way are more flexible and amenable to change, both as a whole and through independent updates to components. Finally this approach enables the integration of ready-built functions, reducing development and maintenance costs and improving application reliability.
Quick deployments and updates are possible
Using a serverless infrastructure, there is no need to upload code to servers or do any backend configuration in order to release a working version of an application. Developers can very quickly upload bits of code and release a new product. They can upload code all at once or one function at a time, since the application is not a single monolithic stack but rather a collection of functions provisioned by the vendor.
This also makes it possible to quickly update, patch, fix, or add new features to an application. It is not necessary to make changes to the whole application; instead, developers can update the application one function at a time.
Code can run closer to the end user, decreasing latency
Because the application is not hosted on an origin server, its code can be run from anywhere. It is therefore possible, depending on the vendor used, to run application functions on servers that are close to the end user. This reduces latency because requests from the user no longer have to travel all the way to an origin server. This matches perfectly with the Fog-to-Cloud approach, and in all location-aware applications where the user’s position triggers a lot of events.
Disadvantages of Serverless computing
Testing and debugging become more challenging
It is difficult to replicate the serverless environment in order to see how code will actually perform once deployed. Debugging is more complicated because developers do not have visibility into backend processes, and because the application is broken up into separate, smaller functions.
Serverless computing introduces new security concerns
When vendors run the entire backend, it may not be possible to fully vet their security, which can especially be a problem for applications that handle personal or sensitive data.
Because companies are not assigned their own discrete physical servers, serverless providers will often be running code from several of their customers on a single server at any given time. This issue of sharing machinery with other parties is known as ‘multitenancy’. Multitenancy can affect application performance and, if the multi-tenant servers are not configured properly, could result in data exposure. Multitenancy has little to no impact for networks that sandbox functions correctly and have powerful enough infrastructure.
Serverless architectures are not built for long-running processes
This limits the kinds of applications that can cost-effectively run in a serverless architecture. Because serverless providers charge for the amount of time code is running, it may cost more to run an application with long-running processes in a serverless infrastructure compared to a traditional one.
Performance may be affected
Because it’s not constantly running, serverless code may need to ‘boot up’ when it is used. This startup time may degrade performance. However, if a piece of code is used regularly, the serverless provider will keep it ready to be activated – a request for this ready-to-go code is called a ‘warm start.’ A request for code that hasn’t been used in a while is called a ‘cold start.’
Vendor lock-in is a risk
Allowing a vendor to provide all backend services for an application inevitably increases reliance on that vendor. Setting up a serverless architecture with one vendor can make it difficult to switch vendors if necessary, especially since each vendor offers slightly different features and workflows.
Microservices can benefit from serverless
The basic idea of microservices is to break down your code into small services which makes it easy to develop, deploy and scale as per the individual requirements. And serverless and FaaS are taking this beyond this!
However, there will be place for both microservices and FaaS. The main reason is that you won’t be able to do everything with functions due to its granularity. For instance, if your API/microservice is going to deal with database, it will be able to respond faster since things are open and ready which won’t be the case with functions.
The important thing to note here is that a group of functions is nothing but a microservice. And hence, functions and microservice can co-exist in a way which is complementary to each other. After all, to an end user it doesn’t make any difference if behind the scenes whether your API is executed as a microservice or a bunch of single app.
Next steps
Serverless technology aims at splitting complex applications in smaller pieces of codes (functions) that can be distributed on all available nodes, even at the edge, where computing nodes have limited resource capabilities. In this way a better distribution of system load can be achieved, the huge amount of data produced at the edge can be processed avoiding the need of transferring this data, so improving the typical latency issues of large IoT scenarios.
In this perspective serverless promise to be an enabling factor for the Fog-to-Cloud efficient implementation: in the mF2C project several usage are under study, in particular in the Use Case 3, that implements proximity marketing services in airport. In this case the proximity processing can be proficiently implemented with FaaS.